|
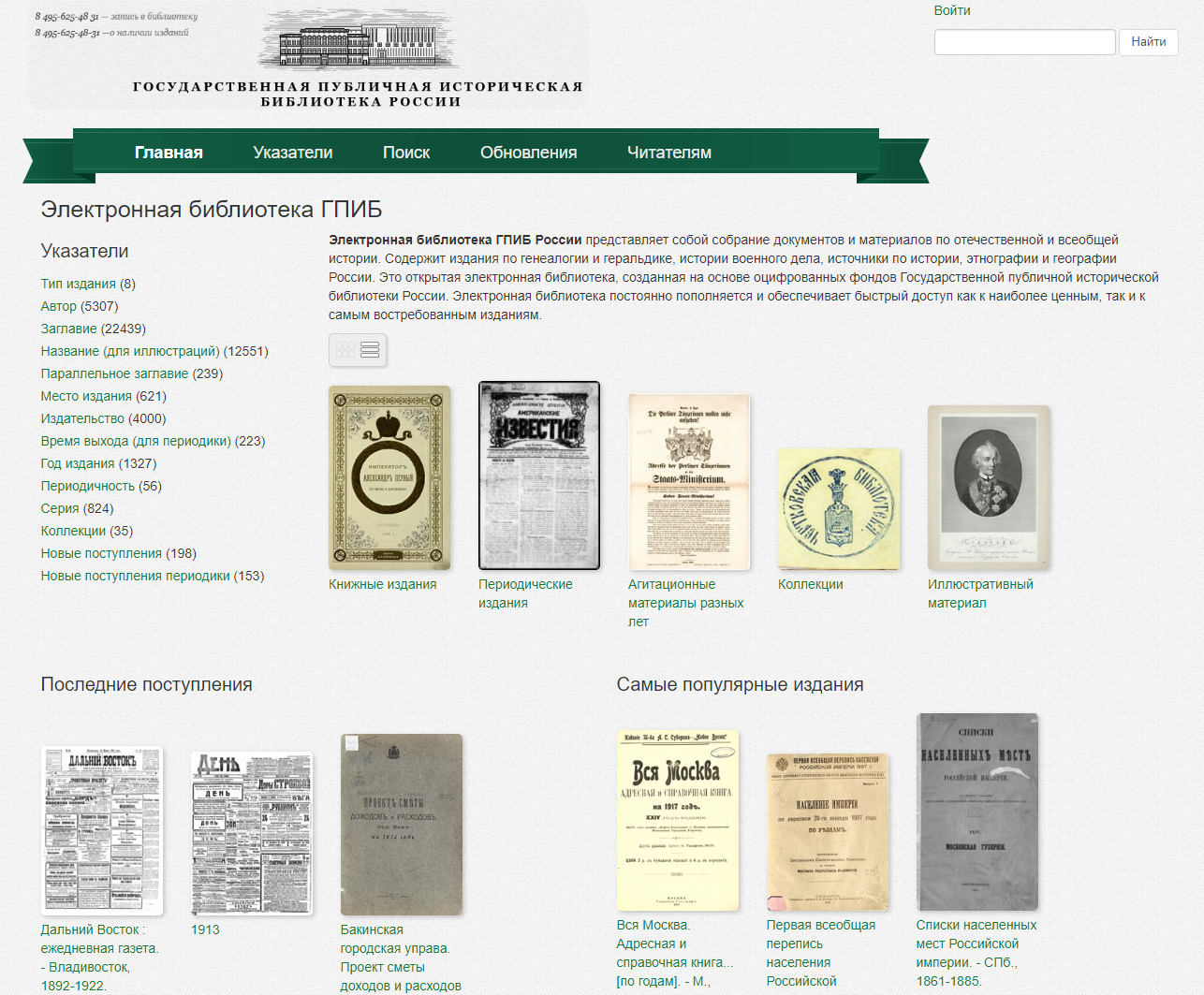
 The online platform was developed by non-profit group dLibrary/InfoRost with a goal to improve access to archival and library collections over the Internet (Why online platform dLibrary/InfoRost was created and its advantages for archivists, librarians and researchers). The platform’s architecture was built to reflect the following main ideas and functionality requirements for online collections: The online platform was developed by non-profit group dLibrary/InfoRost with a goal to improve access to archival and library collections over the Internet (Why online platform dLibrary/InfoRost was created and its advantages for archivists, librarians and researchers). The platform’s architecture was built to reflect the following main ideas and functionality requirements for online collections:
UNIVERSALITY AND SCALABILITY
Designed to handle a variety of material, access venues and services. The platform supports publishing of large, multi-million page collections of
- archival and bibliographic records
- documents
- books, journals, newspapers
- photographs, maps
- audio/video files, etc.
The platform’s intuitive interface was developed based on the needs and information-seeking habits of a large audience of users. The interfaces and metadata displays are flexible and can be changed to reflect specific requirements of collections and material types. This approach supports integration of fragmented collections onto one central platform for improved access.
Archives and libraries require a highly scalable access platform as their needs in digitization and online publishing evolve rapidly. InfoRost platform has a built-in capacity for expansion to accommodate for millions of new document pages, terabytes of data and spikes of simultaneous users during peak times.
LINKED METADATA AND INDEX ACCESS
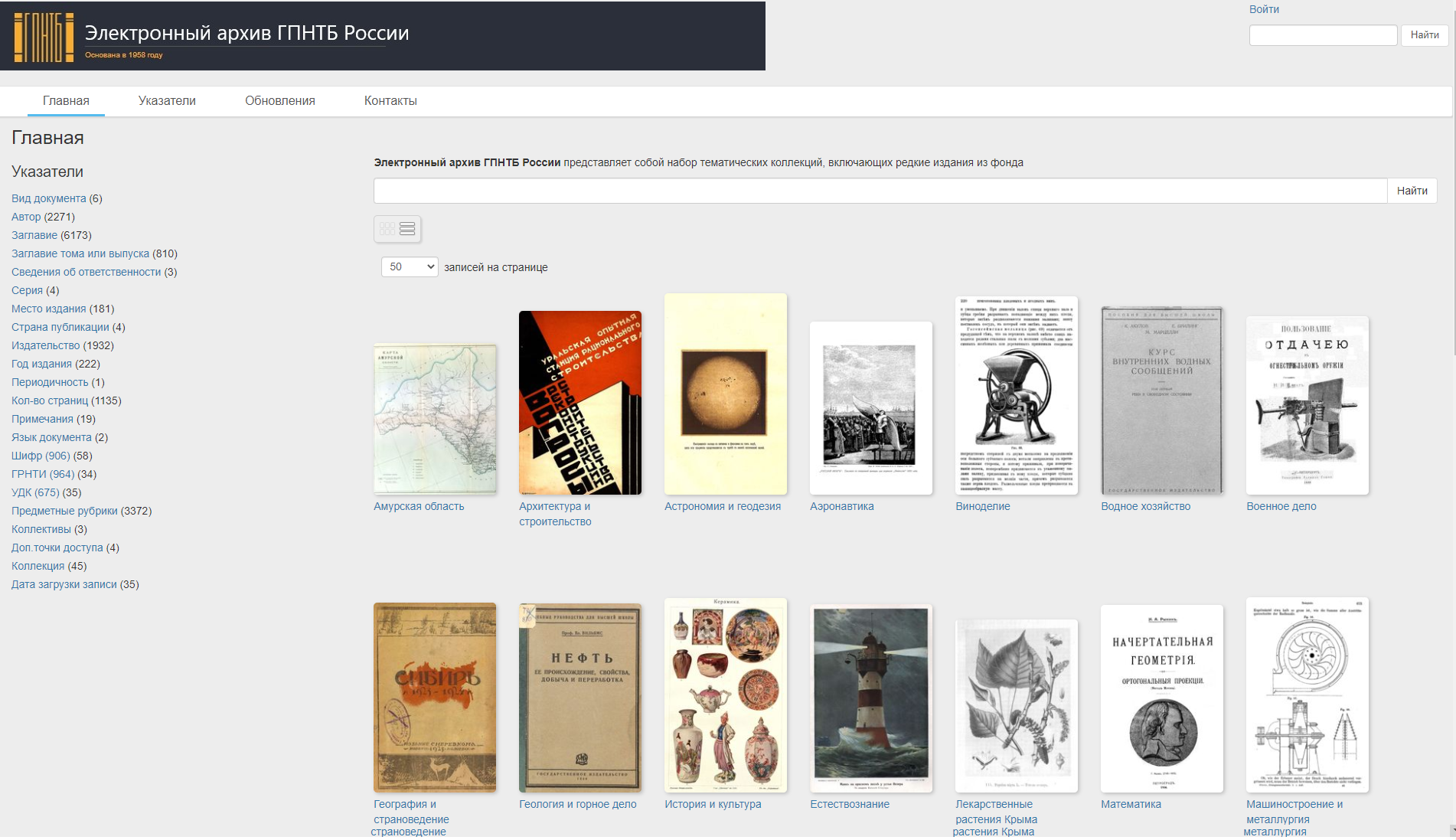
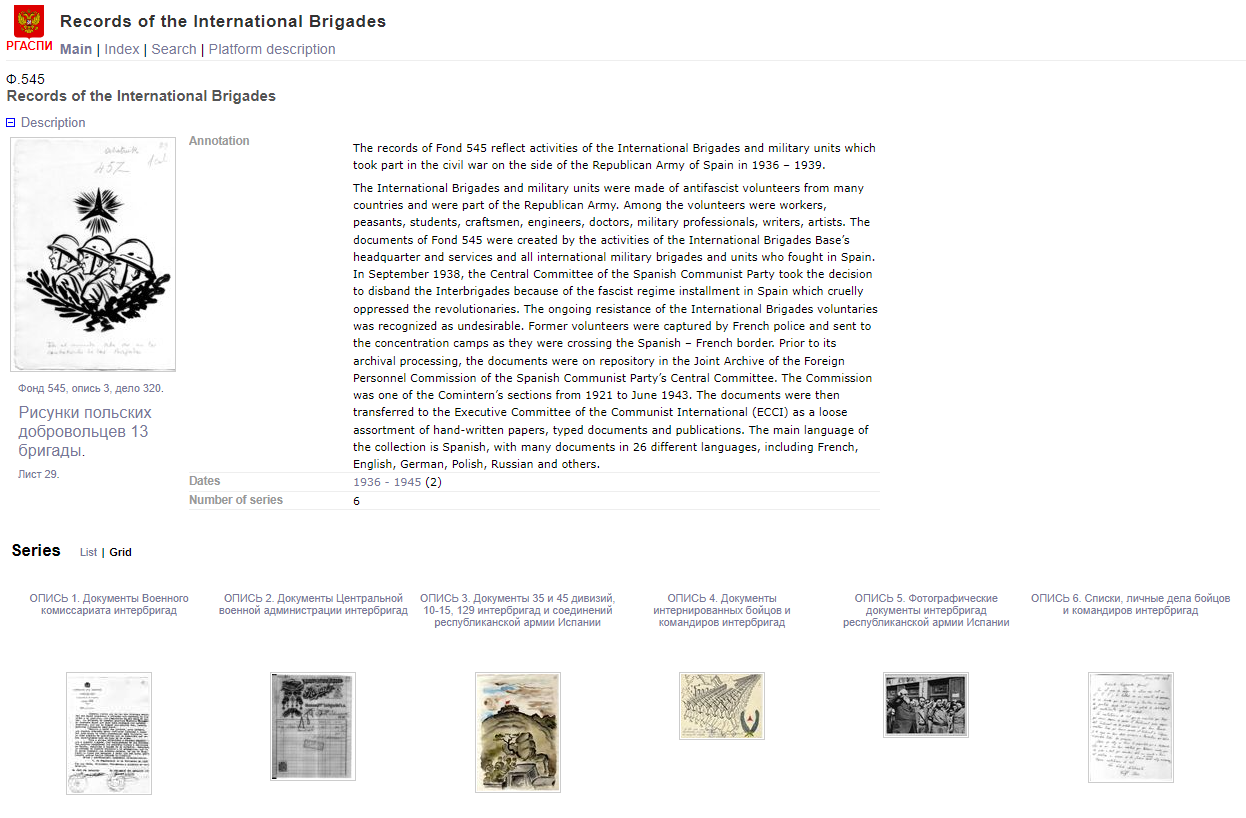
The platform supports an unlimited number of metadata fields which can be interlinked between relevant descriptions. The metadata fields are also aggregated and displayed in browse lists of terms, forming collection-level indexes:
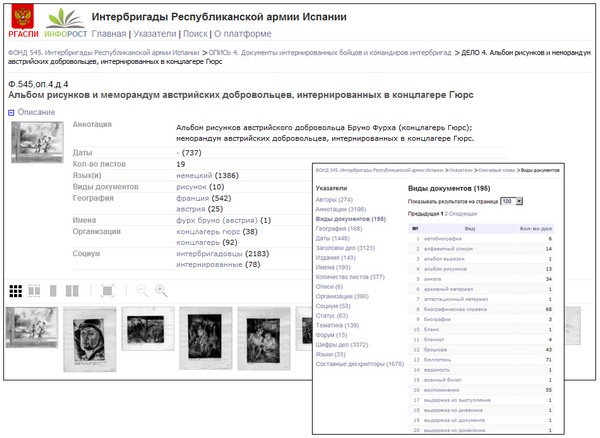
Linked metadata and collection indexes expose relevant terms and provide scholars with multiple access points to documents. The platform features a multi-level hierarchy for the display of finding aids on the record group, series, folder, and document levels. Each collection level provides two views for the lists of lower level objects: a table view with sortable columns and a grid view for images.
The description at each hierarchy level includes the archival ID number, title, annotation, extent of the collection, start and end dates for documents, and descriptors (keywords). The latter includes types such as Author, Document type, Geographic location, Publications, Names, Organizations, Social group, Position, Subject, Forum, and language, as well as compound descriptors.
BIRDS-EYE VIEW BROWSING AND FULL TEXT SEARCHING
The platform interfaces provide several options for intuitive browsing of flat and complex hierarchies of description such as multi-level finding aids. The DocView browser is optimized to display and zoom in/out quickly on hundreds and thousands of document images providing scholars with comprehensive (bird’s-eye) visual overview of large collections. The browser includes grid view, filmstrip browse and page flipping option for bound material:

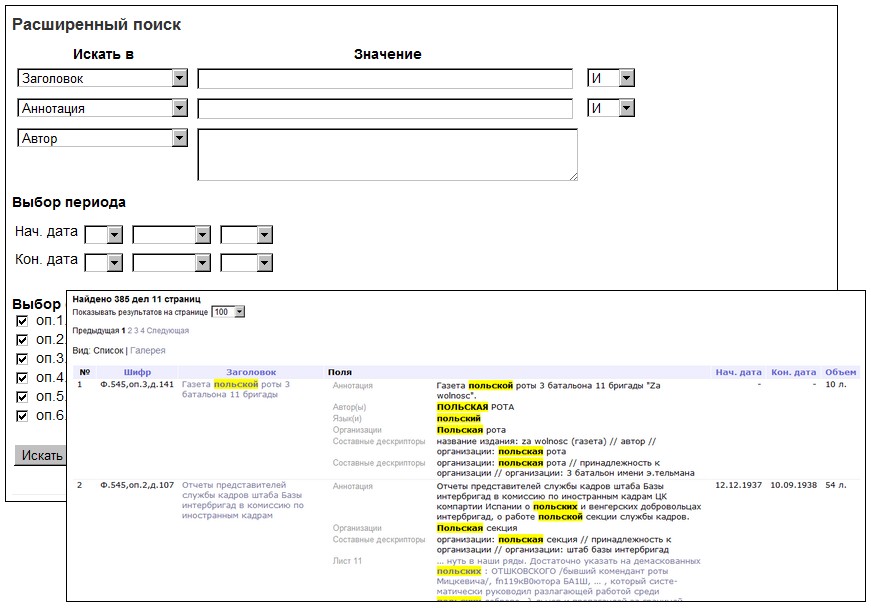
The full-text search engine allows quick searches with found keywords highlighted in the context of a document or its description. The advanced search handles more complex queries for individual fields of descriptions and their combinations (title, annotation, author, language, compound descriptors, start and end dates for documents). The search results can be displayed either as a table with sortable columns (doc IDs, titles, start and end dates) or as a grid of images:
ACCESS CONTROL AND USAGE STATISTICS
The administrative module allows multi-tiered access to records and documents to satisfy specific requirements of any collection. Access can be restricted by username/password or IP address to documents in high resolution only (descriptions and small size document page icons will be available to public) or to any parts of description and full image documents.
The usage statistics module allows monitoring and reporting of each collection’s usage.
SUPPORT OF HIGH VOLUME DIGITIZATION AND RESEARCH PROJECTS
The platform supports integration with scanning equipment and provides tools for automation of image/metadata processing and online publication. All platform tools can be used from local computers or remotely over the Internet. Scanner-platform integration and remote access increase productivity and decrease the cost of high-volume digitization and online publishing operations.
The platform is also optimized to serve as a testbed for research in:
- new forms of online publishing and scholarly communication
- social processing online - archival descriptions, interlinking of documents, improvement of OCR results
- visualization, data mining, GIS
TECHNOLOGY USED
- Ruby programming language
- Ruby on Rails web framework
- MySQL database management system (can be swapped for another DBMS when needed)
- Solr/Elastic Search
    
EVALUATION OF THE PLATFORM
The InfoRost platform was developed by a group of experts in archival and library science, digitization, online publishing and information technologies. The platform received high evaluation from a number of scholars who tested it on the example Records of International Brigades collection (http://interbrigades.inforost.org) at the following organizations:
- Brill Publishers
- Centre d’études des mondes russe, caucasien et centre-européen (Cercec)
- Davis Center for Russian and Eurasian Studies at Harvard University
- Department of Historical Information Science, Moscow State University
- Faculty if History, Higher School of Economics, National Research University (Russia)
- International Institute of Social History (Netherlands)
- Italian Society for the Study of Modern and Contemporary History (SISSCO)
- Russian state archive of social-political history (RGASPI)
- Slavic and East European Collections, Stanford University Libraries
- Stockholm School of Economics
- Vereinigung zur Förderung des Archivwesens (VFA)
     
 


|